I haven’t used my Windows machine for a while now. I was then curious how the reference managers progressed in these periods. I was specially curious about Mendeley because I struggled with that application for some time then.
So, here is my observation: Mendeley stayed the same for the last couple of years. There is no real development; nor any change of any relevant sort since I knew the application. All the icons, the settings, the menus; the features: I see no changes. It is as clumsy as used to be; in many areas. One of the properties that Mendeley sucks at is how reference is downloaded from the internet. It attempts to use Google scholar; combining with its metadata extraction too. What it does is: it attempts to detect some DOI or other identifier to the PDF in the first few pages; and then, use that information to download reference information from Google scholars. For me, the result is a total debacle. It has always been a debacle. Mendeley can detect the papers only less than 5% of the times; as my PDFs don’t typically have metadata information; nor are they always published articles. Many of them are books; or drafts of books, and earlier versions of published articles I received from friends.
My favorite feature of Mendeley, which had been, still is: the BibTex sync feature. I have to admit, I have been tempted to live with Mendeley because of that feature. But, heck, if you have wicked reference data, what is the point of syncing it to Bib file. You will have incomplete citations ultimately. You will be embarrassed in front of colleagues when you realize that your references are incomplete after you sent out the paper. Because of the importance of the feature, I will focus on this feature in comparing the reference managers.
Citavis is not very far better than Mendeley when it comes to reference extraction from the internet. It can even be worse. I was able to download references from the internet only if the book has ISBN numbers or the article has DOI number. Otherwise, manual insertion is the only way I am left with. Look at this tutorial to learn how the process is clumsy in this application: https://youtu.be/MyaW9q_464w?list=PLkLfx87WKrTZTfifTvttqgKwzyQSTDYY5
In Citativ, when you read a PDF file, you can highlight or quote a certain text: comment on it; or give a short title to the comment and the quote. I totally love the idea of giving a short title to the quotation I make from a PDF reading. This feature is also available in Sente. The idea is: you quote a certain sentence or paragraph from the PDF; then, give a title which summarizes the core point of the quote and tag it if you want to. These quotes serve as a short summary of the article. The titles are your reminds of the core points of the quote. It is like summarizing the summary. Very neat approach to reading articles. The neat part in Sente is each of these short quotes could be exported as a separate note file. That means, if you have 20 quotations from the article, you will have 20 short notes: titled appropriately in a folder in finder. The problem with Citavi is each of the quotations are not exportable to separate notes. They can be exported as single file only. That means, it is not any better than reading and annotating a PDF in Acrobat Reader or other PDF readers (PDF exchange; or Foxit in windows: PDF expert in Mac) and exporting a summary.
Qiqq is very different. Its way of extracting references from Google scholars is comparable to Sente. You click the PDF; click BibTex sniffer: you will be given Google scholars to pick the references. If Qiqq failed to detect the title of the PDF correctly, you can manually select the title. Qiqq immediately populates the scholar search with the selected text.
I have given the following book for all the three reference mangers: It was only Qiqq which correctly imported the full reference information.
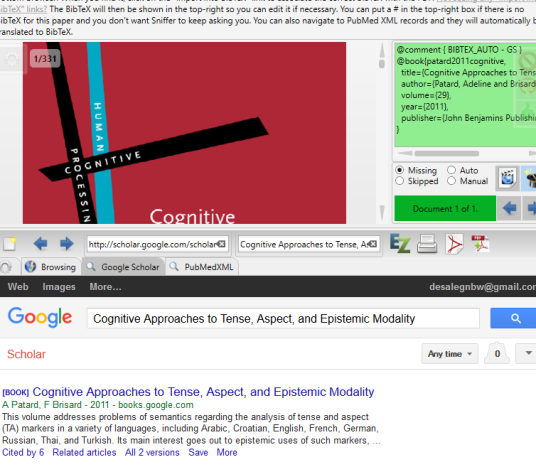
I think the reference downloaded in Qiqq is much better than Sente. Sente has an advantage of downloading from multiple sources like WorldCat; Stanford, British libraries…very good results in some sources, weaker results in others. I used to get the most complete reference data from Stanford library website. But Sente sometimes fails to download the Publisher Field from many sources. Bookends can pick from Google Scholar, Justor and two other sources. But the process of downloading a reference data (called Autocomplete in Bookends; targeted browsing in Sente; BibTex sniffing in Qiqq) is most elegant in Qiqq and Sente.
The other interesting feature of Qiqq is the brainstorming feature: absolutely brilliant tools to play with your references. It can also be used to track the positions one author took over time, how his/her ideas change in the long run. it can also be used to study the history of ideas: where a certain phrase appeared first; then, how other authors reflected that phrase in their publications. Look at these tutorials to see how the Brainstorming works in Qiqq:
My ratting of these reference manager’s capability of downloading references from the internet:
- Mendeley = 4/10
- Zotero= 3/10
- Citavi = 2/10
- Bookends = 7/10
- Sente = 9/10
- Qiqq = 8/10
Why is Sente higher in this ranking?
Because it offers much better choice than Qiqq on the sources. Qiqq does it elegantly on Google scholar; but, it cannot download from other sources which potentially offer more complete reference data.
Conclusion: if I ever have to move to Windows, I will definitely use Qiqq (in combination with OneNote or ConnectedText).
